让你永远都有事情可忙正是前端的魅力所在
按照目前的策略, 博客构建部署大概是以下几个步骤
- 主题内容的webpack打包
- hexo clean && hexo generate
- 图片与对象存储仓库同步
- 生成的html文件的压缩
- public目录中所有文件的拷贝发布
因为不想把主题和内容过多整合, 这样会导致将来更换主题困难
所以计划是把2 3 4 5步骤在构建过程中一键完成
( 虽然有jenkins可以写多步的执行脚本, 但是仍然感觉不够优雅 )
最好是能有个js脚本, 用nodejs一次执行完成这些步骤
第2步之前用的是hexo的命令行工具, 现在可以换成hexo的api, 在js当中调用之
第3步之前已经完成了, 就是用js写的脚本, 简单封装一下拿过来就可以用
第4步目前还没有做到, 准备实现一下, 因为webpack完成了对css和js的压缩输出, 所以静态化后就无需再次处理了
但是html文件是由hexo生成, 所以对主题内容的webpack打包, 是无法完成这件事的
查了一些资料发现gulp可以很简单做到, 于是就计划用它了
第5步, 就在js里面写递归删除与递归拷贝吧
hexo的api
根据官网的介绍, 可以按照下面的方式使用hexo的api
1 | const Hexo = require('hexo') |
上面的写法就如同是在命令行执行hexo clean && hexo generate
正好gulp配置任务的时候也需要返回Promise对象( 下面会提到 ), 可以直接结合, 不需要二次封装了, 不错
gulp

之前没用过这个前端构建工具, 因为跟webpack的作用有不少的重合, 前端实在学不完
这里使用一下它的任务自动管理的功能, 整体的体验挺好
安装
除了gulp本身, 还有其他几个用的到的插件 ( 当然也可以用npm安装 )
1 | # 这几个是gulp相关的 |
gulp在4.0这个大版本做了很大的改变, 这里我使用的是4.0.2
gulpfile.js
在根目录下创建gulpfile.js文件, 这个文件是gulp的配置文件
先简单规划一下结构
1 | const gulp = require('gulp') |
- gulp.task 用于定义一个任务, 第一个参数是任务的名称, 第二个参数是任务要执行的函数
从4.0版本开始, 这个函数必须返回Promise对象, 让gulp来监测该任务是否执行完毕
应该是有利于更优化串行任务的执行过程 default就是在直接执行gulp的时候会执行的任务
当然也可以执行gulp 任务名称用来指定执行某个任务- gulp.series用来定义串行的任务, 也就是把参数里面这几个任务作为子任务, 并按照串行的方式执行
如果不使用它, 而是直接写任务这几个子任务就会以并行的方式执行, 但是在这里因为有执行的顺序要求1
gulp.task('default', ['generate', 'compressHtml', 'syncImages', 'deploy'])
比如必须在generate完成之后再执行html的压缩, 所以选择串行方式
这个api也是gulp4.0新增的
以往只能定义任务的完成依赖, 比如在定义B任务必须在A任务完成后执行1
gulp.task('B', ['A'], ()=>{/* do something */})
添加一些细节
1 | // gulpfile.js |
syncImages里面相关的东西可以看这篇 博客图片迁移记
大体上都一致, 之后又简单封装了一下, 这都不重要accessKey, accessSecret, deployPath这三个参数分别在运行时传入
前两个是网易云对象存储的访问token, deployPath用来指定页面发布的目录, 在deploy当中拷贝到该位置deploy里面写了递归删除目录与递归拷贝目录的函数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78// deploy.js
const fs = require('fs')
const path = require('path')
module.exports = {
/**
* 发布静态化的站点
* @param {String} source 源位置
* @param {String} target 目标位置
* @param {Boolean} copyRoot 是否拷贝根目录
*/
async exec(source, target, copyRoot) {
await new Promise((resolve, reject) => {
console.log(`删除${target}目录中的文件`)
this._deleteFolderRecursive(target, true)
resolve()
})
console.log(`拷贝${source}所有文件 -> ${target}`)
this._copyFolderRecursive(source, target, copyRoot)
},
/**
* 递归删除目录以及子目录中的所有文件
* @param {String} curPath 要递归删除的目录
* @param {Boolean} retainRoot 是否保留根目录不删除
*/
_deleteFolderRecursive(curPath, retainRoot) {
fs.readdirSync(curPath).forEach(file => {
var nextPath = path.resolve(curPath, file)
if(fs.statSync(nextPath).isDirectory()) { // recurse
this._deleteFolderRecursive(nextPath)
} else {
fs.unlinkSync(nextPath)
}
})
if(!retainRoot) { // 根目录保留
fs.rmdirSync(curPath)
}
},
/**
* 递归拷贝目录
* @param {String} source 源位置
* @param {String} target 目标位置
*/
_copyFolderRecursive(source, target) {
let files = fs.readdirSync(source); //同步读取当前目录
files.forEach(file => {
var _src = path.resolve(source, file)
var _target = path.resolve(target, file)
fs.stat(_src,(err,stats) => { //stats 该对象 包含文件属性
if (err) throw err
if (stats.isFile()) { //如果是个文件则拷贝
let readable = fs.createReadStream(_src) //创建读取流
let writable = fs.createWriteStream(_target) //创建写入流
readable.pipe(writable);
} else if (stats.isDirectory()) { //是目录则 递归
this._checkDirectory(_src, _target, this._copyFolderRecursive)
}
})
})
},
/**
* 校验目标目录是否存在
* @param {String} src 源目录
* @param {String} target 目标目录
* @param {Function} callback 回调函数
*/
_checkDirectory (src,target,callback) {
fs.access(target, fs.constants.F_OK, err => {
if (err) {
fs.mkdirSync(target)
}
callback.call(this, src, target)
})
}
}
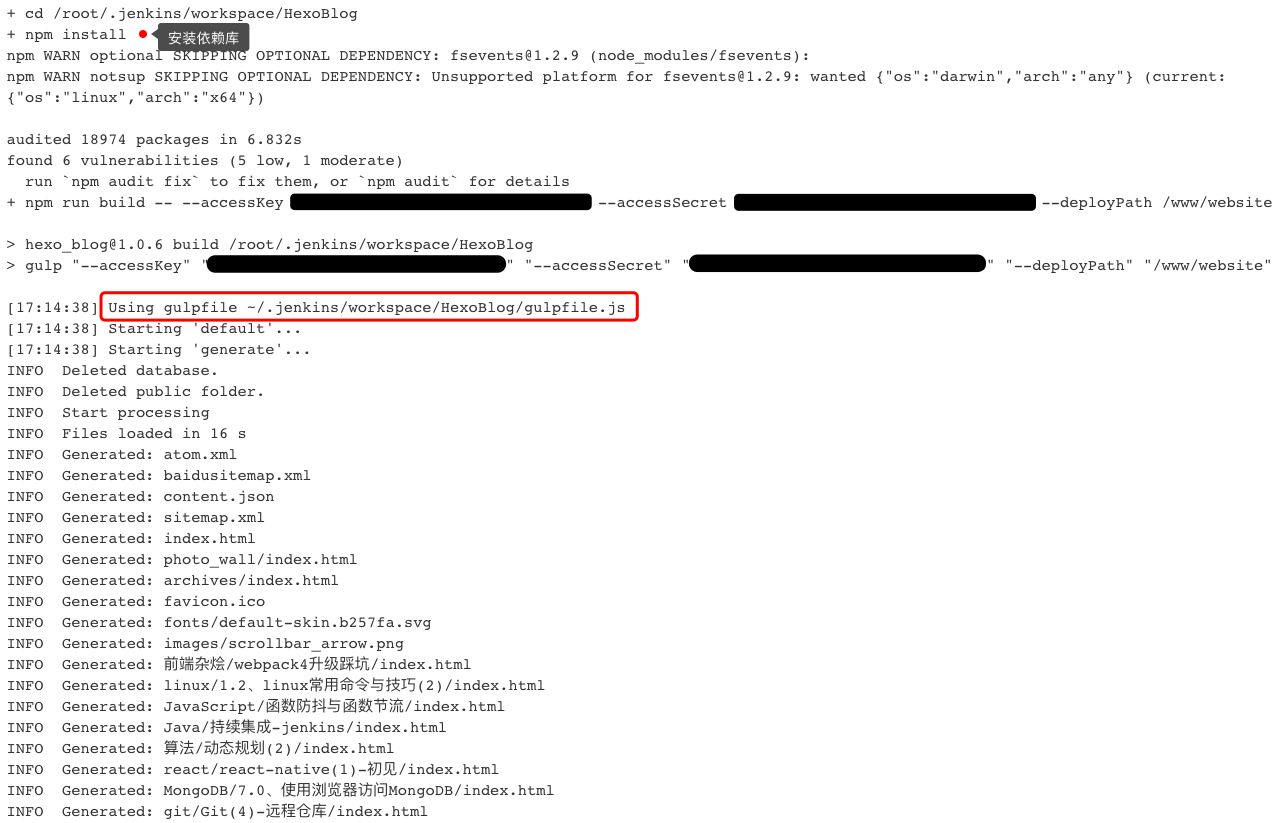
持续集成
在package.json的scripts里面添加 "build": "gulp" 之后, 就可以配置持续集成的脚本了
现在只需要一行了
1 | npm run build -- --accessKey xxx --accessSecret xxx --deployPath /path/to/deploy |
jenkins输出日志