TensorFlow是Google发布的一个机器学习框架,可以构建和训练机器学习模型
把机器学习的应用门槛降低了很多
并且有对应的js版本,可以在nodejs或者浏览器环境运行
基础知识准备
张量(Tensors)
tf.Tensor是TensorFlow.js中的最重要的数据单元,它是一个形状为一维或多维数组组成的数值的集合。tf.Tensor和多维数组其实非常的相似。
一个tf.Tensor还包含如下属性:
rank: 张量的维度shape: 每个维度的数据大小,代表了张量的形状dtype: 张量中的数据类型
1 | import * as tf from '@tensorflow/tfjs-node' |
从上述执行结果可以发现,超出边界的数据会被舍弃
tf.tensor函数包含三个参数,后两个参数是可选的
- values: 原始数据
- shape: 数组,指定每个维度的数据大小(不指定则根据原始数据的多维数组层级决定)
- dtype: 数据类型,只能是下面的几种值

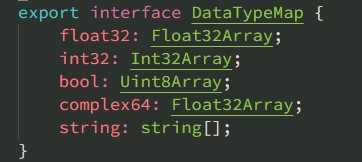
操作
张量可以进行一些处理和运算,但是张量对象本身是不可变的
这些操作都会产生新的张量对象
改变形状
1 | const a = tf.tensor([[1, 2], [3, 4]]); |
上述代码表示将张量改变为第一层维度的长度为4,第二层维度的长度为1
运算
1 | // 对所有数据平方 |
1 | // 将两个张量逐个相加 |
执行add的情况两个张量的形状和数据类型必须一致
模型训练
作为一个初见HelloWorld,这是一个垃圾分类识别图片的demo
使用nodejs环境来执行这个过程
1、安装nodejs版本的TensorFlow
1 | npm install @tensorflow/tfjs-node |
当然它底层是在调用C++库,在windows环境需要使用node-gyp进行编译
相比之下,mac和linux环境安装会顺利很多
为了代码的编写方便,我也添加了TypeScript的基础环境
1 | "dependencies": { |
2、准备训练素材
下载地址
这里有4种类型的垃圾,每一种里面都有大量的图片
3、读取训练素材
这里主要就是一些nodejs当中读写文件的API
1 | /* |
这里拿到的imageData是一个包含所有训练素材路径和类别索引的数组
4、图片数据转化为张量
1 | /** |
5、对大量训练素材进行处理
由于直接把所有图片读取后转化为张量,会占用大量内存
TensorFlow支持使用生成器函数进行分批处理
imageData为第3步中得到的图片路径数据
1 | // 将图片数据打乱顺序 便于观察训练效果 |
6、加载模型进行复用
这里使用MobileNet这个模型进行复用
所需文件:
model.json
group1-shard1of1.bin
1 | // 加载模型 |
7、执行训练
如果是一次性读取所有文件,直接使用fit方法
如果是生成器函数分批读取的,使用fitDataset方法
1 | // 使用fit方法进行训练(让模型参数尽可能拟合图片数据) |
执行完毕后,就在output里面得到了训练好的模型文件