总字数 776
预计阅读时间 3 分钟
为了验证HashMap的工作原理 , 先创建一个JavaBean实体类
1 | public class Country { |
需要注意的是这个类重写了hashCode和equals方法
hashCode方法在name字符串的长度为奇数和偶数的时候会返回不同的常数值
equals方法则是忽略大小写比较name属性是否相同
调试执行以下代码
1 | public static void main(String[] args) { |
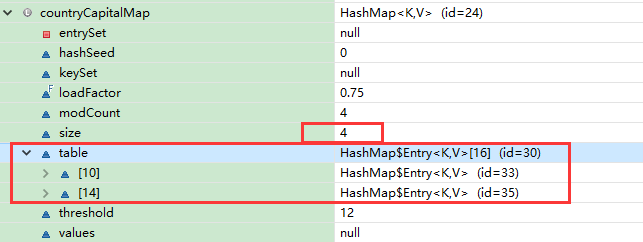
发现这个Map当中存在4个Entry ( 一组键值对构成的对象 )
但是在table这个存放Entry的数组当中只有两个位置有数据
这两个位置上又分别使用链表的结构存放了两个Entry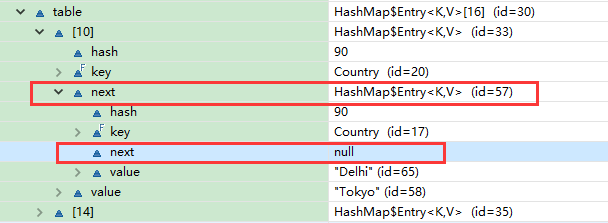
由上述现象可以总结出
HashMap是一个由数组和链表结合构成的复合型的数据结构
某一个Entry存放在哪个数组索引上 , 是由该键的hashCode方法的返回值决定的
如果两个键存在相同的哈希值( 也称为哈希冲突 ) , 那么将保存在同一个索引上面 , 以链表的形式存在
当向这个链表末尾追加元素时 , 需要对这个链表进行迭代
在这个迭代过程中 , 会使用键的equals方法进行比较 , 如果在某个链表节点上获得了true的结果
那么新的Entry会替换掉这个原有的链表节点
如果遍历该链表后没有发现重复的元素 , 那么该Entry将追加到该链表末尾
所以当向Map当中存放数据的时候 , “键”的对象最好是一个不可变的对象
但是对象本身是否可变并不是问题的关键
而是该对象是否会产生稳定的哈希值 ( 也就是hashCode方法的返回值 )
如果某些因素导致了哈希值的变化 , 虽然该元素仍然在Map当中存在
但是已经无法用get方法拿到其对应的值
总结
- HashMap有一个叫做Entry的内部类,它用来存储key-value对。
- 上面的Entry对象是存储在一个叫做table的Entry数组中。
- table的索引在逻辑上叫做“桶”(bucket),它存储了链表的第一个元素。
- key的hashcode()方法用来找到Entry对象所在的桶。
- 如果两个key有相同的hash值,他们会被放在table数组的同一个桶里面。
- key的equals()方法用来确保key的唯一性。
- value对象的equals()和hashcode()方法根本一点用也没有。