最近发现了一个提供全文检索服务的Algolia, 可以上传内容索引并且提供访问接口执行全文检索
可惜尝试之后发现上传内容索引时如果内容太长就会失败, 这就导致只能在摘要范围内搜索
因为已经有了后端API的支持, 所以考虑自己实现一下
分词
全文检索的关键步骤是分词, 中文分词做的比较好的就是jieba分词了
还提供了nodejs的包可以直接调用
当然底层仍是C++代码, 安装依赖时需要使用node-gyp编译
我在windows环境始终没能成功(已安装python和windows-build-tools), linux和mac环境倒是十分顺利
基本的调用方式
1 | import * as nodejieba from 'nodejieba' |
对于文章内容和查询关键字都需要做分词操作
保存分词结果
在mongodb当中使用两个集合分别保存文章正文和分词结果
(因为mongodb限制每个文档的最大体积16MB, 这样做也是为了避免长文章导致的无法保存)
article集合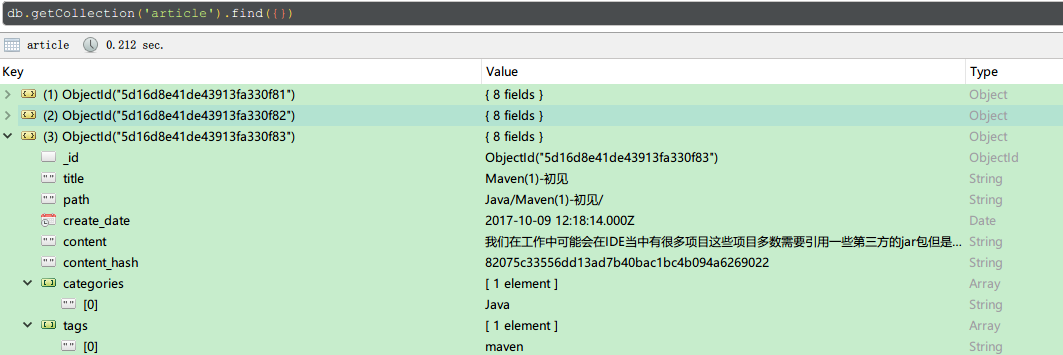
article_keys集合
这个集合用来保存分词的结果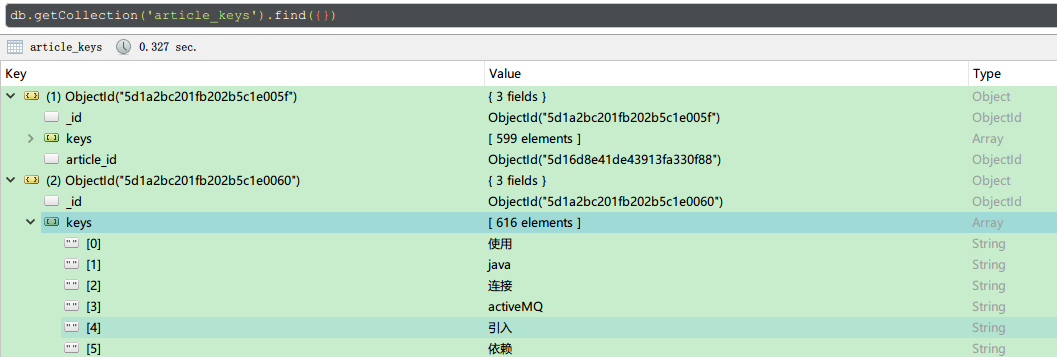
执行检索
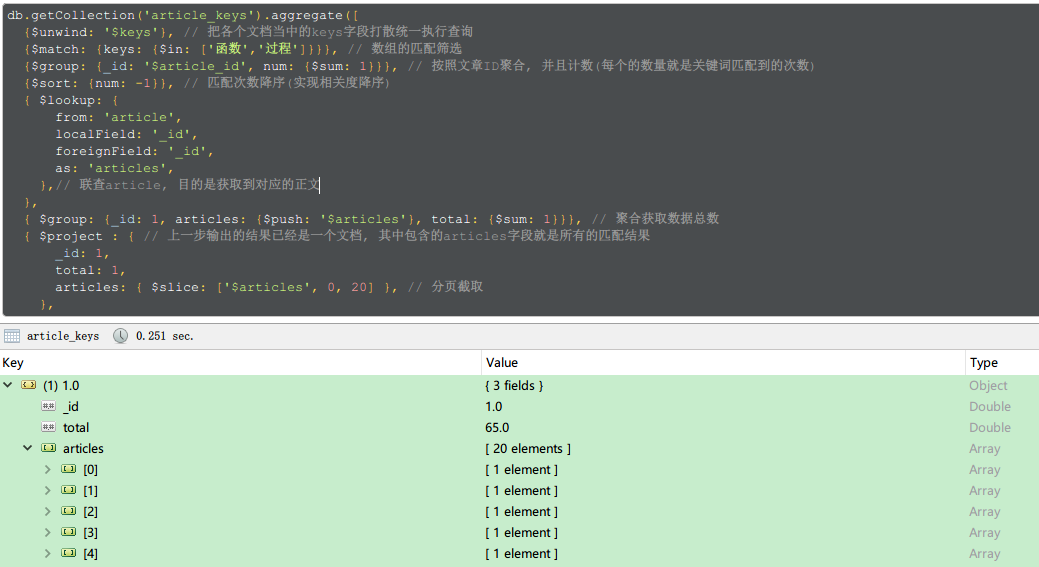
需要重点理解一下mongodb的aggregate, 这是一个管道操作, 接受一个数组
数组中的每个元素都是一步操作, 前一步操作的执行结果传递给下一步操作继续处理
检索需要实现以下几个目标
- 自动分词: 比如”函数解决”这类常见中文词汇, 自动拆分为”函数”,”解决”
- 强制分词: 比如”存储 过程”其中包含空白符分隔的, 强制拆分为”存储”,”过程”
- 非完全匹配: 比如分词为”函数”,”解决”, “函数”有匹配, “解决”无匹配, 也能查到”函数”匹配的
- 相关度降序: 出现频率高的文章在前, 比如”函数”,”解决”在A文章共出现5次, B文章共出现3次, 则A文章在前
- 摘要提取: 对于关键词所在正文内容提取, 关键词出现位置靠近则合并提取范围, 关键词过多则省略靠后的摘要
1和2可以利用jieba分词和正则做到, 查询过程主要实现3和4, 5在查询之后对正文处理做到
以下是目前设计的查询方案
主要目的是在一次查询当中做到计数和分页截取
1 | const splitedWords = ['函数', '过程'] //对查询关键词的分词处理结果 |
操作输出的结果就是包含分页数据和数据总数的一个对象了
需要注意的是, 倒数第二步执行聚合之后, 因为已经聚合为一个文档, 所以就不能再用$skip和$limit了
只能使用数组的操作函数$slice, 第一个参数为操作对象, 第二个参数是截取起点, 第三个参数是截取长度
摘要提取
这里是TypeScript语法, 使用原生JavaScript也一样
1 | /** |
主要思路就是找到每一个关键词所在位置, 确定截取区域, 注意几点
- 截取区域到达全文开头或者末尾的处理
- 截取范围按照升序排列以便截取后组合的结果正确
- 两个相邻的关键词如果截取范围相连或者有重叠, 需要将两者的范围合并
- 摘要总长度限制
性能表现
分词后的数据总量大约56万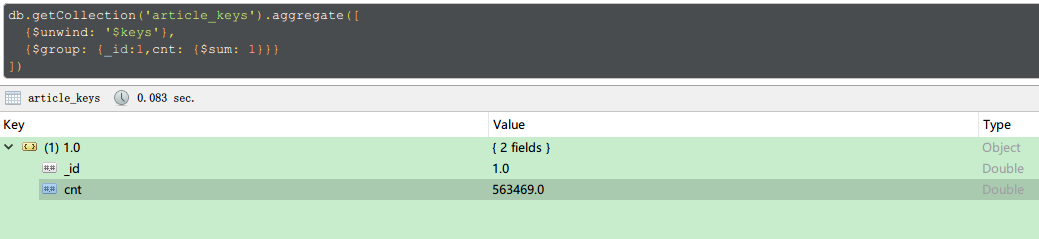
添加索引之后基本每次查询的时间大约200ms, 基本还是不错的