RegExp对象
在JavaScript当中, RegExp对象表示正则表达式
创建RegExp对象有两种方式
- 常量 :
let reg = /hello\n/g后面的g是修饰符, 表示全局匹配; 这里的 / 是表示正则表达式的边界, 不属于内容
- 构造函数 :
let reg = new RegExp('hello\\n', 'g')修饰符是作为第二个参数传入的, 第一个参数是正则内容的字符串, 所以对于反斜杠需要转义
正则表达式的构成
正则表达式由两种基本字符类型构成
- 原义字符 : 表示这个字符的原本意思
- 元字符 : 在正则表达式当中具备特殊含义, 如果要让元字符表达其本身含义(也就是作为原义字符使用), 需要加 *\* 进行转义
各种元字符
$匹配输入字符串的结尾位置。如果设置了RegExp对象的Multiline属性,则也匹配 ‘n’ 或 ‘r’。()标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。*匹配前面的子表达式零次或多次。+匹配前面的子表达式一次或多次。.匹配除换行符 \n 之外的任何单字符。[]标记一个中括号表达式的开始和结束位置, 常用于表示范围。{}标记限定符表达式的开始。|指明两项之间的一个选择(“或者”的含义)。?匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。\将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。^匹配输入字符串的开始位置,除非在方括号表达式中使用,此时它表示不接受该字符集合(“非”的含义)。
边界
| 字符 | 含义 |
|---|---|
| ^ | 以指定的字符开始 |
| $ | 以指定的字符结束 |
| \b | 单词边界 |
| \B | 非单词边界 |
例如
1 | // eg.1 以AB或者AC开头 |
虽然说单词边界找的是空白字符, 也就是\s
但是上面的eg.3却不能用\s, 会导致单词之间的空格也被替换掉
范围类
如果要匹配某个范围的其中一个字符
那么可以使用[]
例如
1 | // eg.1 穷举的范围 |
预定义类
其实就是一些预定义的范围类
为了使正则书写更简洁
\cX匹配由x指明的控制字符。例如, cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 \c 视为一个原义的 ‘c’ 字符。\f匹配一个换页符。等价于 x0c 和 cL。\n匹配一个换行符。等价于 x0a 和 cJ。\r匹配一个回车符。等价于 x0d 和 cM。\t匹配一个制表符。等价于 x09 和 cI。\v匹配一个垂直制表符。等价于 x0b 和 cK\s匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [\f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。\S匹配任何非空白字符。
| 字符 | 等价类 | 含义 |
|---|---|---|
| . | [^\r\n] | 除了回车和换行符之外的所有字符 |
| \d | [0-9] | 数字字符 |
| \D | [^0-9] | 非数字字符 |
| \s | [\t\n\x0B\f\r] | 空白符 |
| \S | [^\t\n\x0B\f\r] | 非空白符 |
| \w | [a-zA-Z0-9_] | 单词字符(大小写字母 数字 下划线) |
| \W | [^a-zA-Z0-9_] | 非单词字符 |
量词
用于指定某个组合出现的数量
| 字符 | 含义 |
|---|---|
| ? | 0次或1次 |
| + | 1次或多次 |
| * | 任意次数 |
| {n} | 出现n次 |
| {n,m} | 出现n到m次(包含n与m) |
| {n,} | 至少出现n次 |
例如
1 | // 以1个或多个数字结尾 |
贪婪模式
正则针对字符串从左向右进行解析, 每个部分都会尽可能多地去匹配字符, 这称之为贪婪模式
例如
1 | let reg = /^\d{2,5}/ |
按照这个正则的规则, 匹配2到5个数字都是可以的
但是它实际执行的时候是按照最多的方式来匹配的, 也就是默认的匹配模式是贪婪模式
如果要使用非贪婪模式, 需要在量词后面加上?
1 | let reg = /^\d{2,5}?/ |
分支条件
使用|来代表分支条件, 也就是匹配前后的任何一个规则即可
比如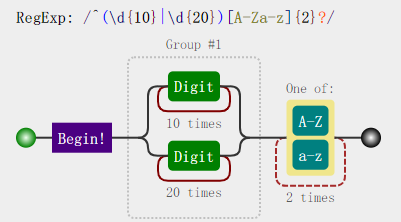
表示字符串整体包含10个数字或者20个数字, 并且最后有2个字母
注意 : 这个 | 分割的是左右两边所有部分,而不是仅仅连着这个符号的左右两部分
所以需要加括号, 否则会一直涵盖到表达式的边界或者遇到下一个 |
断言
如果字符串中存在2个数字后面跟着2个字母, 就把这2个数字替换掉
如果只是这样写\d{2}[a-zA-Z]{2}
那么后面跟着的2个字母也会被替换掉
要实现这种需求, 就必须用到断言
由于正则是将字符串从左到右进行解析, 左侧可以称之为头部, 右侧可以称之为尾部
从头部向尾部移动可以称之为向前走
判断前面是什么可以称之为前瞻
JavaScript只支持前瞻, 而不能去判断后面是什么(后顾)
对于上面的需求, 就可以利用断言来做了
1 | let reg = /\d{2}(?=[a-zA-Z]{2})/ |
语法规则
| 名称 | 正则语法 | 含义 |
|---|---|---|
| 零宽正向前瞻 | exp(?=assert) | 我前面是符合assert的 |
| 零宽负向前瞻 | exp(?!assert) | 我前面的是不符合assert的 |
| 零宽正向后顾 | exp(?<=assert) | 我后面是符合assert的 |
| 零宽负向后顾 | exp(?<!assert) | 我后面是不符合assert的 |
如同^代表开头,$代表结尾,\b代表单词边界一样,前瞻断言和后顾断言也有类似的特点,它们只匹配某些位置
在匹配过程中,不占用字符,所以被称为零宽
分组
当我们需要把某个部分看做一个整体添加量词的时候, 就要给这个部分添加()
也就是作为一个分组
(也包括上面的分支条件的边界位置)
未添加分组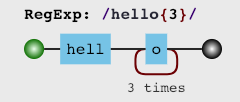
添加分组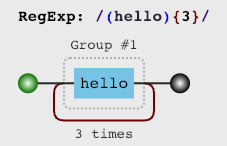
添加分组之后, 分组后面跟着的量词就会作用于整体
分组的引用
正则在解析的过程中会对分组进行编号(从1开始)
我们可以通过\数字的方式对分组进行引用, 从而实现一些需求
例如
要匹配两个连续的数字, 并且这两个数字不同
要让后一个数字和前一个数字不同
就必须要引用前一个数字, 那么只能对分组进行引用
同时配合零宽负向前瞻
1 | let reg = /(\d{1})(?!\1)\d{1}/ |
(\d{1})这里代表的是匹配一个数字, 这个简单(?!\1)这里代表的是后面的字符与第一分组不同(但是不占用字符)\d{1}这里代表后面还是一个数字
所以就可以达到匹配两个连续数字, 并且这两个数字不同了