修饰符
修饰符是作用于整个表达式的附加属性
对于两种创建RegExp对象的方式
有各自对应的指定修饰符的语法
1 | let reg1 = /^\w+$/g |
g: 全局搜索, 对应RegExp对象中的global属性i: 忽略大小写, 对应RegExp对象中的ignoreCase属性m: 多行搜索, 对应RegExp对象中的multiline属性
关于multiline
g全局搜索 和 i忽略大小写都很容易理解m多行搜索, 有以下的特性
- 字符串中没有换行符(可以是\r\n或者\n), m修饰符没有作用
- 正则表达式中没有^或$匹配字符串的开头或结尾, m修饰符没有作用
多行字符串的语法
- 可以在字符串中加入\n
- 可以使用ES6的字符串模板语法
1
2
3
4var str1 = `ab
cd`
// 等价于
var str2 = `ab\ncd`
正则表达式多行匹配
1 | const singleline = /^ab/ |
对于具备multiline属性的正则对象^由原本的匹配整个字符串的开头, 变为匹配每一行的开头$由原本的匹配整个字符串的结尾, 变为匹配每一行的结尾
所以^和$都没有的, 添加m修饰符是不起作用的
RegExp对象中的其他属性
- lastIndex : 当前表达式匹配内容的最后一个字符的下一个位置
- source : 正则表达式的文本字符串
RegExp对象内置方法
test
test方法用于检测一个字符串是否匹配指定的正则, 返回true或false
1 | const reg1 = /\d/ |
test的检测功能本身很简单, 但是正则加上g修饰符之后, 表现就有了变化
当这个正则对象是全局搜索时
每次执行test方法
- 如果返回true, 那么lastIndex属性就会更新至当前匹配内容的下一个字符的索引
比如第一次执行reg2.test(‘12’), 返回true, lastIndex就变为1
下次执行test的时候, 就会从lastIndex开始找, 而不是从字符串的头部开始找 - 如果返回false, 那么lastIndex属性就会重置为0
所以第三次调用reg2.test(‘12’)的时候, 才会返回false
exec
这个方法用于使用正则表达式对字符串执行搜索
如果字符串中找不到匹配的结果则返回null
否则返回一个数组
- 第一个元素是在字符串当中匹配到的子串
- 第二个元素是第一分组对应的子串(如果有第一分组)
- 第三个元素是第二分组对应的子串(如果有第二分组)
……
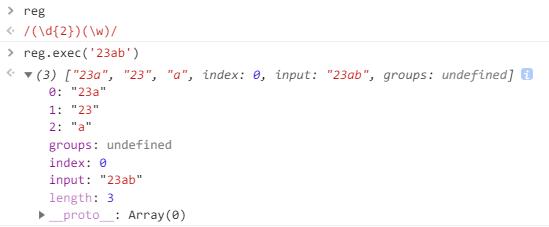
如果正则对象具备全局搜索, 特点和test类似
也会更新RegExp对象的lastIndex
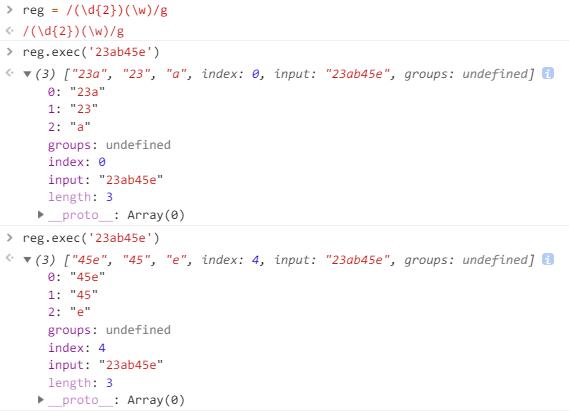
所以如果要逐个获取每次的匹配结果
只要RegExp对象具备全局搜索, 循环执行exec即可
String对象中的方法
search
方法返回第一个匹配结果的索引,查找不到返回-1
search方法会忽略g标志,总是从字符串的开头进行检索
例如
1 | var reg = /\d[a-z]/ |
match
如果正则表达式不带g
那么与exec方法的执行结果完全相同
如果正则表达式带g
返回的就是逐次匹配结果构成的数组
(相当于是逐次执行exec, 把每次执行结果的第一个元素拿出来, 全都放进一个数组里)

split
split方法用于把一个字符串使用正则分隔为若干个字符串组成的数组
1 | '1a2b3c'.split(/\d/) // ["", "a", "b", "c"] |
需要注意的是如果头部或尾部存在匹配该正则的部分, 就会多出一个空串
split的参数也可以传入一个字符串, 就会把字符串的内容作为原义字符放入正则当中执行处理
replace
正则带g就替换所有, 不带就替换第一个
1 | var str = "2018-11-26"; |
replace的第二个参数还可以传入一个函数
没有分组的情况
例如, 我要把字符串里面所有的整数都找出来, 全都乘以2
1 | // match是匹配到的字符串 |
match当然是字符串类型, 这里只是借用了js的隐式类型转换, 对字符串做乘法直接转换为Number, 无法完成转换的就是NaN
有分组的情况
1 | // $1是第一分组, $2是第二分组 |
如果有更多分组, 那么函数被调用时就会传入更多参数